新闻动态
第二期统计咨询案例线上分享会顺利举行
时间:2022-10-29
2022年10月28日下午14时,由中国人民大学智能数据云及全面量化开发跨学科交叉平台推出的第二期统计咨询案例线上分享会顺利举行。中国人民大学统计学院副教授王菲菲以“基于机器学习方法的民事诉讼案件繁简分流研究”为题作了精彩分享,本期分享会由中国人民大学统计学院副教授黄丹阳主持。

黄丹阳首先介绍了分享嘉宾的相关信息。王菲菲是中国人民大学统计学院副教授。主持并参与了国家自科基金项目、教育部社科重大项目、国家重点研发项目等多个课题。注重文本挖掘及其商业应用、社交网络分析、大数据建模等方面的研究。在Journal of Econometric, Journal of Business and Econometric Statistics, Journal of Machine Learning Research, 中国科学(数学)等国内外高水平期刊上发表多篇论文。
王菲菲首先介绍了报告的背景。国家重点研发计划“基于人工智能的高效智能审判辅助关键技术及装备研究”中有六个子课题围绕智能审判的不同方面展开研究,王菲菲聚焦于第二个子课题“案件简繁智能分流技术研究”。她对“繁简分流”这一概念作了介绍,繁简分流是指民事案件在立案后,通过定性分析,将复杂案件与简单案件区别开来,是智慧法院建设中的重要组成部分。繁简分流实现简案快办,繁案精办,有效解决“案多人少”的难题,提高司法效率,减少当事人诉讼成本,维护人民群众的合法权益,已在全国多地试点实施。但是,繁简分流主观性较强,且民事简易程序的适用可能会增大法官审案压力,这些都在一定程度上限制了繁简分流提高司法效率的能力。为了改进繁简案件甄别标准,优化繁简分流流程,对民事案件进行更科学合理的繁简分流,王菲菲所在的研究团队采用机器学习模型这一鲜有前人涉足的研究方向,使用自然语言处理与大数据技术,希望能提升繁简分流的客观科学性,这为大数据技术在司法行业日后的发展做出了初步的创新性尝试。

为了更好地展示分析流程,王菲菲以信用卡纠纷案由为例展开了后续介绍。首先对问题进行需求分析,将“如何繁简智能分流”这个大的需求拆解成“如何提取繁简分流的关键信息”、“如何利用抽取的繁简分流的关键信息”、“如何为法院提供个性化繁简分流指导”三个更为细致的需求,然后团队主要针对前两个需求,进行数据预处理、描述分析等一系列操作构建出模型并作模型评估,最后分析结果。
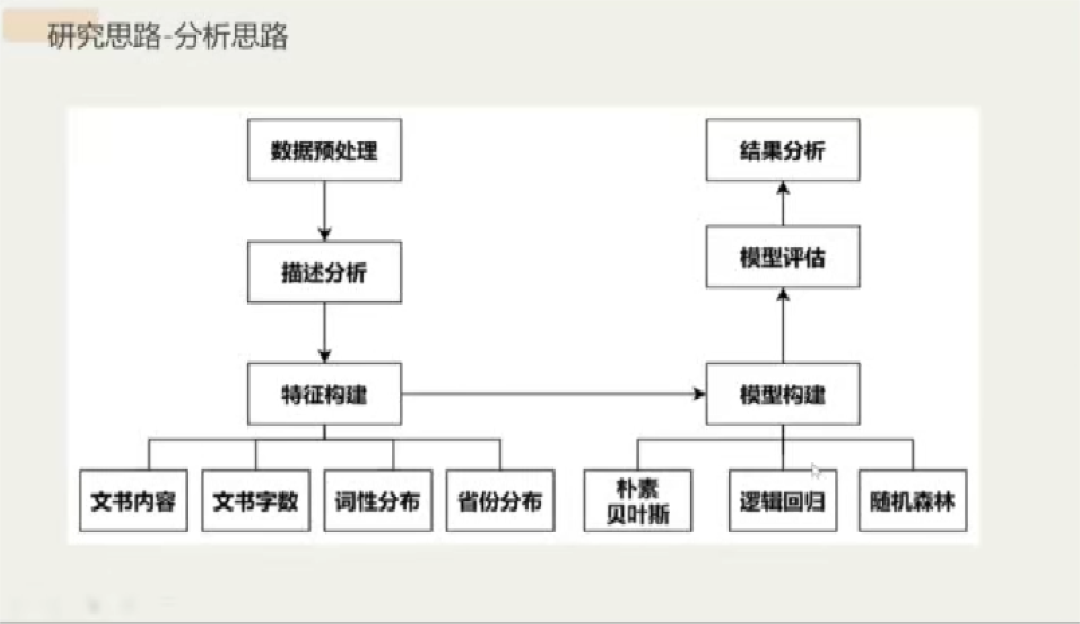
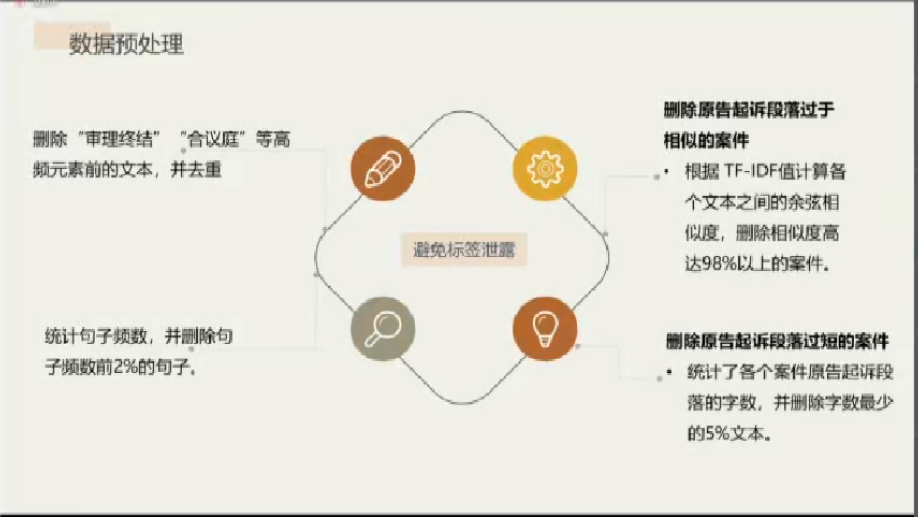
接着,王菲菲向大家说明了数据来源和数据预处理的具体操作。以法院文书标志的区别作为判断繁案简案的标准(因变量Y),将起诉段文本(自变量X)用于模型的训练和构建。在数据预处理阶段,需要删除一些特定的高频元素前的文本并去重、根据TF-IDF值删除与原告起诉段落过于相似的案件、统计并删除原告起诉段落过短以及一般化程度过高的句子,以避免标签泄露。
随后,王菲菲使用多种可视化方式对数据进行了描述分析。基于信用卡纠纷案由,用词云图展示繁简案原告起诉段的内容,发现二者关键词相似,但不同关键词出现的频率不同;用箱线图统计繁简案原告起诉段的字数,发现简案原告起诉段字数更多,繁案原告起诉段字数分布更分散,极端值更多;用饼图统计繁简案原告起诉段的词性分布情况,发现二者结构占比非常接近,不同词性占比虽存在差距但较为细微,因此用词性来区分繁简案可能相对比较困难。此后,再从词性分布、文本分析、判决法院省份三个方面进行特征的构建。
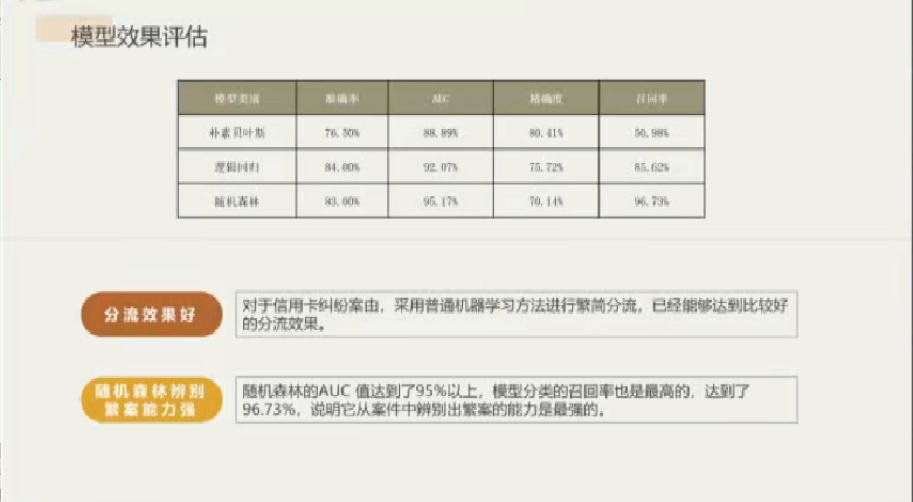
描述分析完毕,王菲菲向大家展示了量化结果。模型的构建使用到了朴素贝叶斯、逻辑回归、随机森林三个常见的分类器,经评估发现模型效果很好,因此无需使用更高级而复杂的分类器。评估还发现,该模型分流效果好,其中随机森林分类的召回率最高,辨别繁简案能力尤为突出,为三者中最强。王菲菲指出,以词频作为自变量去构造对文本的分类器时,往往会得到分类效果好而可解释性不强的结果。若希望可解释性提升,有两种思路:可以作主题筛选来让文本变得有解释性,也可以事先给定有意义的词,在研究过程中专看这些词的效果。
报告的最后,王菲菲对系统实践及研究成果进行了简要介绍,并对本次报告作了总结与展望。

提问环节中,王菲菲就引入主题模型的可能性、案由的分类方法、如何挖掘关键词等问题作了认真细致的解答,与师生们进行了更进一步的探讨。